揭秘大數(shù)據(jù)分析基石 Hadoop數(shù)據(jù)服務(wù)
大數(shù)據(jù)分析已成為現(xiàn)代商業(yè)決策和科學(xué)研究的核心驅(qū)動(dòng)力,而Hadoop作為其最著名的開源框架,構(gòu)成了處理海量數(shù)據(jù)的基石。理解Hadoop數(shù)據(jù)服務(wù),是深入大數(shù)據(jù)世界的關(guān)鍵一步。
一、 Hadoop的核心:一個(gè)分布式系統(tǒng)框架
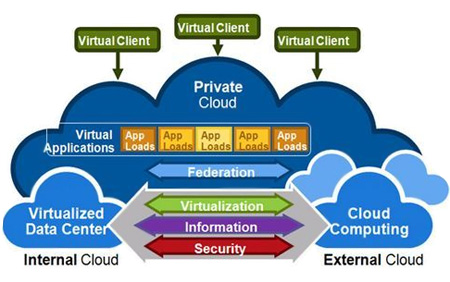
Hadoop并非單一軟件,而是一個(gè)由Apache基金會(huì)維護(hù)的、允許使用簡單編程模型在跨計(jì)算機(jī)集群上分布式處理海量數(shù)據(jù)集的生態(tài)系統(tǒng)。它的設(shè)計(jì)初衷是解決傳統(tǒng)數(shù)據(jù)庫和服務(wù)器在規(guī)模(Volume)、速度(Velocity)和多樣性(Variety)上的“三V”挑戰(zhàn)。其核心優(yōu)勢在于高可靠性、高擴(kuò)展性及高容錯(cuò)性——通過廉價(jià)的商用硬件集群,即可存儲(chǔ)和處理PB級甚至更大量的數(shù)據(jù)。
二、 Hadoop數(shù)據(jù)服務(wù)的兩大支柱:HDFS與MapReduce
Hadoop的數(shù)據(jù)服務(wù)能力主要建立在兩大核心組件之上:
- HDFS(Hadoop Distributed File System,分布式文件系統(tǒng)):
- 角色:數(shù)據(jù)的“倉庫”。它將超大文件分割成多個(gè)數(shù)據(jù)塊(通常為128MB或256MB),并將這些塊冗余存儲(chǔ)(默認(rèn)3份副本)在集群的多臺(tái)機(jī)器上。
- 核心思想:“移動(dòng)計(jì)算比移動(dòng)數(shù)據(jù)更劃算”。計(jì)算任務(wù)會(huì)被直接調(diào)度到存儲(chǔ)有所需數(shù)據(jù)塊的節(jié)點(diǎn)上執(zhí)行,極大減少了網(wǎng)絡(luò)傳輸開銷。
- MapReduce:
- 角色:數(shù)據(jù)的“加工廠”。它是一種編程模型,用于對HDFS中的大規(guī)模數(shù)據(jù)集進(jìn)行并行計(jì)算。
- 工作流程:分為兩個(gè)主要階段。Map(映射)階段:將輸入數(shù)據(jù)拆分,由多個(gè)節(jié)點(diǎn)并行處理,生成中間鍵值對。Reduce(歸約)階段:將Map階段輸出的、具有相同鍵的中間結(jié)果進(jìn)行匯總和計(jì)算,產(chǎn)生最終結(jié)果。這種“分而治之”的思想使得處理海量數(shù)據(jù)成為可能。
三、 超越核心:豐富的Hadoop生態(tài)系統(tǒng)
現(xiàn)代Hadoop數(shù)據(jù)服務(wù)早已超越了最初的HDFS+MapReduce組合,形成了一個(gè)功能強(qiáng)大的工具生態(tài)系統(tǒng),以應(yīng)對更復(fù)雜的數(shù)據(jù)處理需求:
- 數(shù)據(jù)管理與查詢:
- Hive:提供類似SQL的查詢語言(HiveQL),將查詢轉(zhuǎn)換為MapReduce或更高效的Tez/Spark任務(wù),讓熟悉SQL的分析師也能處理大數(shù)據(jù)。
- HBase:一個(gè)構(gòu)建在HDFS之上的分布式、列式NoSQL數(shù)據(jù)庫,支持實(shí)時(shí)讀寫和隨機(jī)訪問海量數(shù)據(jù)。
- 數(shù)據(jù)采集與傳輸:
- Flume, Sqoop:用于高效地收集、聚合和移動(dòng)大量日志數(shù)據(jù)(Flume)或在Hadoop和關(guān)系數(shù)據(jù)庫之間傳輸數(shù)據(jù)(Sqoop)。
- 資源管理與調(diào)度:
- YARN(Yet Another Resource Negotiator):Hadoop 2.0引入的核心組件,作為集群的資源管理和作業(yè)調(diào)度層。它將資源管理與數(shù)據(jù)處理邏輯解耦,使得Spark、Flink、Tez等更多計(jì)算框架可以運(yùn)行在同一個(gè)Hadoop集群上,極大地提升了集群的利用率和靈活性。
- 高級計(jì)算引擎:
- Apache Spark:雖然常與Hadoop并列,但它通常運(yùn)行在YARN之上,利用內(nèi)存計(jì)算提供比MapReduce快數(shù)十倍至百倍的迭代計(jì)算和流處理能力,已成為當(dāng)前大數(shù)據(jù)處理的主流選擇之一。
四、 Hadoop數(shù)據(jù)服務(wù)的典型應(yīng)用場景
Hadoop及其生態(tài)系統(tǒng)廣泛應(yīng)用于:
- 海量數(shù)據(jù)存儲(chǔ)與歸檔:利用HDFS低成本、高可靠的特點(diǎn),存儲(chǔ)原始日志、歷史交易記錄、傳感器數(shù)據(jù)等。
- 批量數(shù)據(jù)處理與分析:如網(wǎng)站點(diǎn)擊流分析、用戶行為分析、ETL(提取、轉(zhuǎn)換、加載)過程、機(jī)器學(xué)習(xí)模型訓(xùn)練等。
- 數(shù)據(jù)倉庫與商業(yè)智能(BI):通過Hive等工具,構(gòu)建企業(yè)級數(shù)據(jù)倉庫,支持復(fù)雜的報(bào)表和即席查詢。
- 推薦系統(tǒng):基于用戶歷史行為大數(shù)據(jù),進(jìn)行協(xié)同過濾等算法計(jì)算,實(shí)現(xiàn)個(gè)性化推薦。
- 日志與事件處理:實(shí)時(shí)或準(zhǔn)實(shí)時(shí)地收集和分析服務(wù)器、應(yīng)用程序產(chǎn)生的日志,用于監(jiān)控和故障排查。
五、 與展望
Hadoop數(shù)據(jù)服務(wù)通過其分布式存儲(chǔ)和并行計(jì)算的根本設(shè)計(jì),為大數(shù)據(jù)分析提供了堅(jiān)實(shí)、可擴(kuò)展的基礎(chǔ)設(shè)施。盡管MapReduce因其批處理延遲在某些實(shí)時(shí)場景中被Spark、Flink等更快的引擎部分取代,但HDFS和YARN作為存儲(chǔ)和資源管理的基石,仍然是許多大型企業(yè)大數(shù)據(jù)平臺(tái)不可或缺的部分。理解Hadoop,就是理解了大數(shù)據(jù)技術(shù)演進(jìn)的起點(diǎn)和核心架構(gòu)思想。隨著云原生和存算分離架構(gòu)的發(fā)展,Hadoop也在不斷進(jìn)化,但其“化整為零,并行處理”的精髓將持續(xù)影響未來數(shù)據(jù)處理技術(shù)的發(fā)展。
如若轉(zhuǎn)載,請注明出處:http://m.babypapa.cn/product/3.html
更新時(shí)間:2026-05-24 00:50:19